Using AI as a search engine has become a standard practice, both for everyday tasks and for work. People rely on it to find documentation, locate the best deals, or quickly compare options. During peak shopping periods, it’s natural to turn to AI for help with the overwhelming amount of information. A simple, harmless prompt like:
“Where can I buy Brand X sneakers in Y country at a discount price?”
Seems like the perfect shortcut, right?
I asked exactly that question, expecting the AI to point me to the store with the best deal. At first glance, the response looked normal: a list of “trustworthy discount websites”. It included the brand’s “official” local store, an outlet site, another “official” retailer, and an Amazon link, which turned out to be the only legitimate one.
A quick investigation revealed the truth: the majority were scam sites. One even claimed to be a local brand (when the brand is from the other side of the globe). These were low-effort storefronts, displaying products on a plain table layout, with self-signed certificates issued only a week prior.
The AI Model had confidently recommended me a list of fake discount sites. No error messages, no warnings. Just clean, friendly, weaponized misinformation. A symptom of something bigger.
How Data Poisoning Alters AI Behavior
Modern AI Models ingest enormous amounts of data from user interactions, public websites, documentation, product reviews, online repositories, forums, and basically any source of information there is to imagine. When any of these sources becomes polluted, the model’s behavior changes. Sometimes it takes an outage for anyone to realize something is wrong.
What I encountered was a straightforward example of data poisoning. According to OWASP LLM04:2025, which defines this type of threat:
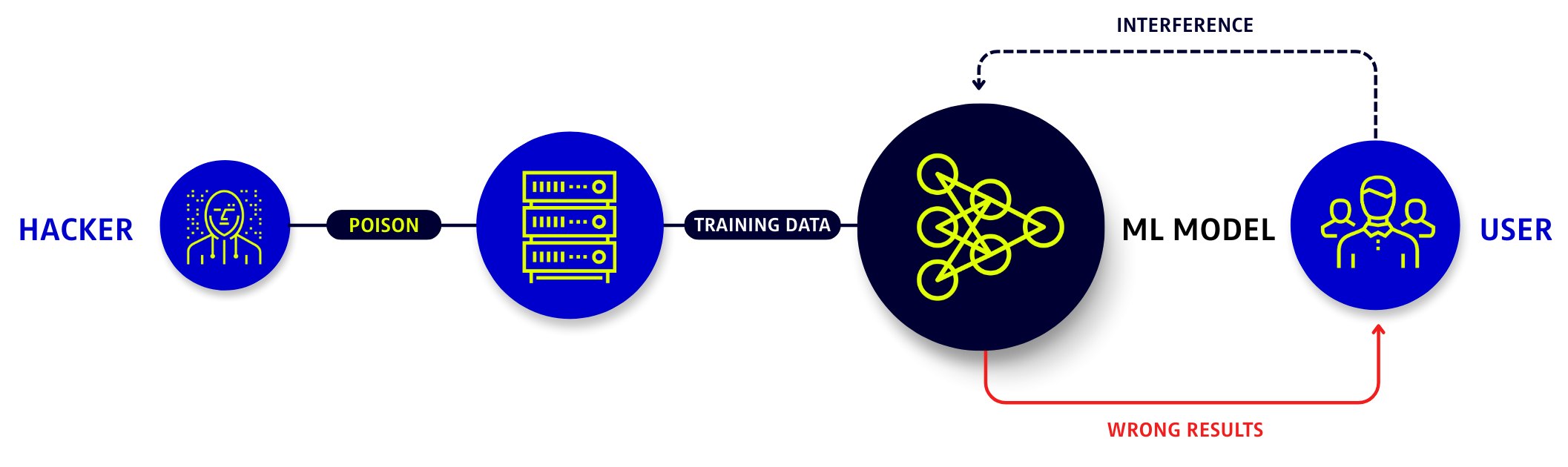
Attackers can target multiple stages of the LLM lifecycle, including:
- Pre-training: Learning from general data.
- Fine-tuning: Adapting models to specific tasks.
- Embedding: Converting text into numerical vectors.
Regardless of the stage exploited, the result is similar: a slow, almost imperceptible behavioral shift that can evade even the most attentive teams.
Below, we are going to analyze some real-world scenarios, along with some “fingerprints” this poison can leave in the AI Models.
Scam Recommendations
Returning to the initial example, the poisoned model began recommending:
- Newly registered domains.
- Questionable discount sites (“90% off plus free shipping!”).
- Pages with no reputation history.
Cause: Poisoned associations between products and scam sites seeded in scraped online forums.
Malicious or Non-Existent Software Libraries
Developer-facing AI Models are increasingly targeted because a single poisoned recommendation can compromise entire pipelines. Poisoning may appear as:
- Recommendations for NPM or PyPI packages that don’t exist, except for recently published typosquats.
- Suggested repositories that have been hijacked or altered.
- Command-line instructions pointing to deprecated or malicious URLs.
Cause: Attackers training the model with fake documentation, repositories, or Q&A posts that get ingested downstream.
Sudden Obsession with Unknown Brands or Entities
Poisoned models often start forcing irrelevant or unfamiliar entities into responses:
- Obscure product names.
- Unknown professionals.
- Niche crypto platforms and currencies.
- Unfamiliar software.
- Unfamiliar financial services.
Cause: Entity insertion poisoning. Attackers create fake online footprints to push visibility for their services.
Directional Drift in Model Behavior
A model that used to be a reliable source, suddenly:
- Misclassifies in the same direction.
- Gives overly confident wrong answers.
- Favors specific vendors or tools.
- Changes tone or emphasis in a narrow topic area.
Cause: Poisoned slice of data affecting one domain.
Quiet Anomalies in Internal Metrics
An AI Model that has been stable for months suddenly shows an unexplained drop on a specific evaluation slice. Some early signs to watch for are:
- Unusual shifts in embedding clusters.
- Sudden performance drops in specific evaluation categories.
- Spikes in similar user prompts from suspicious IP ranges.
Cause: Poisoned incremental fine-tuning, bot-driven feedback manipulation, or contaminated data sources.
| SCENARIO | FINANCE | EDUCATION | HEALTHCARE | TECHNOLOGY |
|---|---|---|---|---|
| Scam Recommendation | Model points users to fake banking or investment sites, leading to credential theft. | Model lists illegitimate “scholarship portals” that collect student data. | AI suggests unlicensed online pharmacies selling counterfeit medications. | AI recommends phishing look-alike SaaS tools for “cheaper licenses.” |
| Malicious or Non-Existent Software Libraries | Typosquatted library introduced into risk-model codebases. | Compromised LMS plugin recommended for classroom analytics. | Suggests a fake medical-device SDK that includes malware. | AI recommends a rogue NPM/PyPI package containing a backdoor. |
| Sudden Obsession with Unknown Brands or Entities | Fabricated “crypto analysts” or investment firms promoted as trustworthy. | Nonexistent “educational research institutes” cited as authorities. | Fake clinical trial groups or supplement brands suddenly recommended. | Nonexistent “developer consortiums” or vendors appearing in answers. |
| Directional Drift in Model Behavior | Model starts favoring risky investment products or biased credit signals. | AI begins over-recommending certain publishers or prep services. | Model shifts toward specific drugs, insurers, or treatments without cause. | AI consistently pushes certain cloud vendors or tools without justification. |
| Quiet Anomalies in Internal Metrics | Small accuracy drops on fraud-detection or KYC tasks without code changes. | Decline in grading consistency on specific subjects or question types. | Reduced reliability in drug-interaction or symptom-triage slices. | Embedding clusters shift, weakening search or code-assist performance. |
AI data poisoning can quietly destabilize entire systems by corrupting the information and logic that organizations rely on. Because poisoned models still appear to function normally, they can influence decisions, workflows, and automations long before anyone notices something is wrong. In high-stakes domains (like finance, education, healthcare, and technology) this means trusted AI outputs may gradually become biased, unsafe, or strategically manipulated.
The consequences range from financial losses and service disruptions to compromised safety, degraded learning outcomes, and weakened security across interconnected systems. Over time, these distortions erode institutional trust, create openings for fraud or exploitation, and undermine the reliability of AI-driven processes that organizations depend on. In essence, data poisoning doesn’t simply mislead models. It quietly shifts reality for the people and systems that rely on them.
Building a Defense Against Data Poisoning
Model poisoning thrives in the gaps. gaps in data lineage, in vendor controls, in monitoring, and in the assumptions teams make about where their model’s “knowledge” comes from. The good news is that organizations can materially reduce the risk of poisoning by adopting a structured, supply-chain-aware approach to AI development. Below is a practical checklist provided by OWASP that teams can integrate into their workflows to strengthen resilience against these attacks and ensure the model’s behavior remains aligned, verifiable, and trustworthy:
- Track data origins and transformations using tools to perform dynamic analysis of third-party software.
- Vet data vendors rigorously, and validate model outputs against trusted sources to detect signs of poisoning.
- Implement strict sandboxing to limit model exposure to unverified data sources. Use anomaly detection techniques to filter out adversarial data.
- Tailor models for different use cases by using specific datasets for fine-tuning.
- Ensure sufficient infrastructure controls to prevent the model from accessing unintended data sources.
- Use data version control (DVC) to track changes in datasets and detect manipulation.
- Store user-supplied information in a vector database, allowing adjustments without re-training the entire model.
- Test model robustness with red team campaigns and adversarial techniques to minimize the impact of data perturbations.
- Monitor training loss and analyze model behavior for signs of poisoning using thresholds.
- During inference, integrate Retrieval-Augmented Generation (RAG) and grounding techniques to reduce risks of hallucinations.

The lesson is clear:
We cannot treat AI outputs as reflections of neutral truth. They are reflections of the data that shaped them, data that is increasingly adversarial, manipulated, and strategically engineered. Protecting the integrity of that data is no longer a niche security task, but a core requirement for business resilience, consumer trust, and societal safety.
This is where AI Governance becomes essential. Effective governance establishes clear accountability for how AI systems are designed, trained, deployed and monitored, ensuring the data sources are trustworhy. Without governance, even well-intentioned AI initiatives can drift into opaque systems no one fully controls or can confidently defent.
Organizations that succeed in the next era of AI will be those that take data provenance as seriously as code provenance, treat model behavior as a continuously monitored asset, and invest early in safeguards that make poisoning detectable rather than catastrophic. The shift isn't just operational. It’s cultural.
AI security is no longer optional. It is the foundation upon which every future AI capability will stand. Those who act now will define the standards the rest of the industry will eventually follow. Those who wait will inherit models they can’t explain, can’t defend, and ultimately can’t trust.